Accord Book is built around a core promise: when a team asks for project context, the system returns the decisions, constraints, and history that still matter now.
Benchmarking retrieval is how we hold that promise to account.
Here is what the April 2026 evaluation showed.
The benchmark run
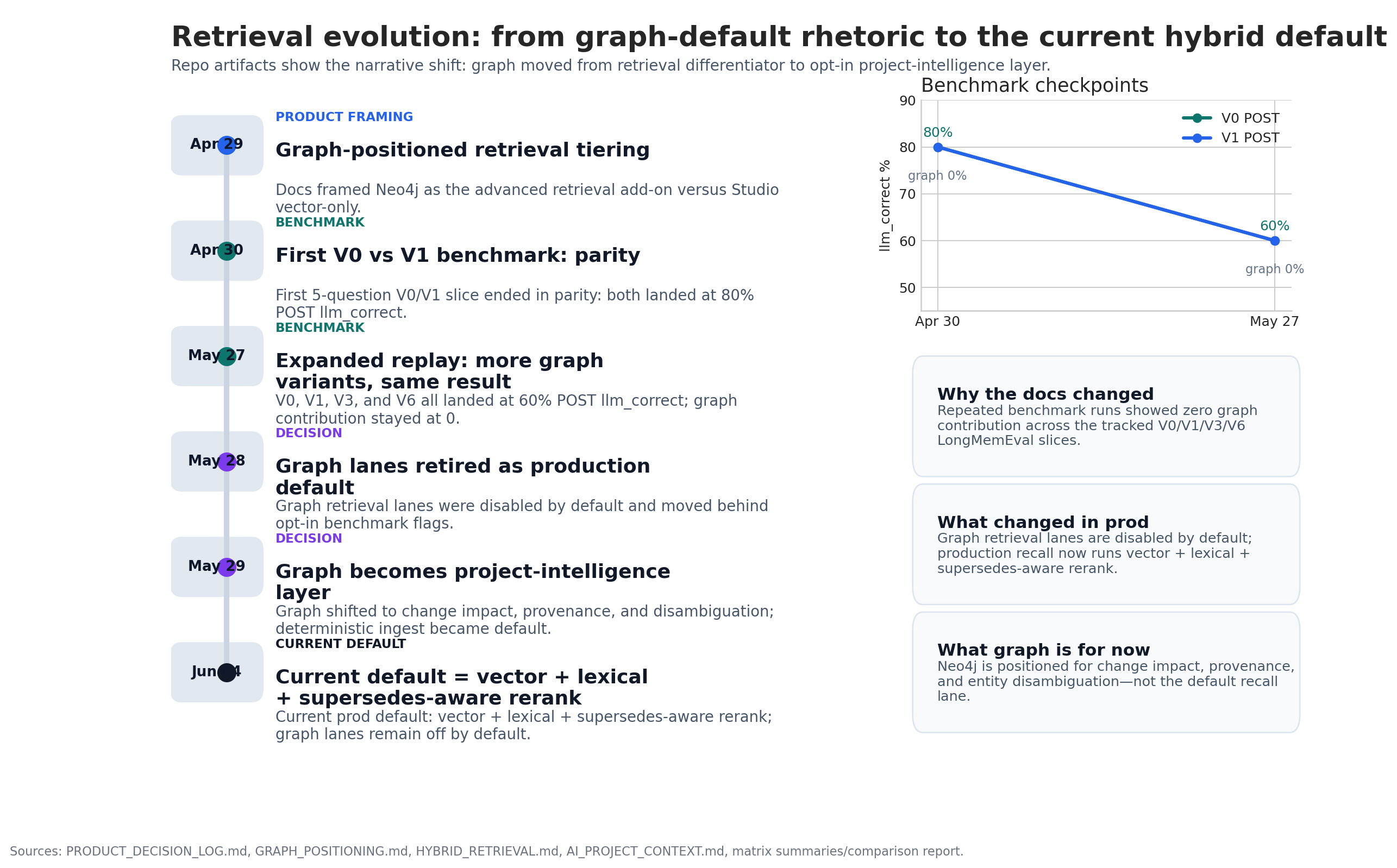
The April 22, 2026 LongMemEval-style production-fit analysis ran against a 20-entry benchmark subset. Every threshold passed:
| Metric | Baseline | Treatment | Threshold | Result |
|---|---|---|---|---|
| Retrieval p95 | 1431.4 ms | 990.1 ms | < 1500 ms | Pass |
POST-curation llm_correct |
90.0% | 90.0% | >= 70% | Pass |
| Extraction p95 / max | 517.0 s / 536 s | — | < 600 s | Pass |
| Worst curation stage max | 76 s | — | < 180 s | Pass |
| API 4xx/5xx | 0 | 0 | 0 | Pass |
These numbers reflect an end-to-end run through ingestion, extraction, curation, retrieval, and LLM-based judging — not an isolated search test.
Three things this confirmed
1. The pipeline works end-to-end
Accord Book's retrieval was benchmarked through the full stack: ingestion, extraction, curation, retrieval, and judging. That is a stronger signal than a standalone vector similarity test and validates the architecture as a system, not just individual components.
2. Judge-based evaluation surfaces what string matching misses
The run recorded 80% on string match and 90% on judged correctness. In a project-memory system, correct answers are often grounded and materially accurate without matching a stored fixture verbatim. LLM-based judge evaluation is the right tool for that distinction.
3. Supersedes-aware reranking improved latency without trading accuracy
The treatment path hit 990ms retrieval p95 against 1431ms for the baseline — roughly a 30% improvement — while holding the same judged correctness. That validates continued investment in the retrieval stack as an engineered system, not just a vector index.
What's next
The April run used a 20-entry subset. Upcoming work includes validating against a larger dataset, evaluating the graph-enabled retrieval path on entity-dense project scenarios, and expanding the benchmark suite as Accord Book moves toward broader pilot availability.
For the full retrieval architecture story, read Why Production Retrieval Needs More Than Vector Search. For the graph-positioning decision, read How We Decide When Graph Belongs on the Retrieval Path.