Vector search is one of the most useful primitives in modern AI systems.
It is also one of the easiest to over-trust.
If your job is to find semantically similar text, embeddings can take you a long way.
If your job is to reconstruct the current state of a changing project from scattered evidence, vector search is only the opening move.
That is the retrieval problem Accord Book is built around.
The real production problem: current-state reconstruction
Teams do not ask retrieval systems for semantically related paragraphs. They ask for operationally useful context:
- what is current,
- what changed,
- what replaced the old decision,
- what evidence supports this answer,
- and what an owner or agent should trust enough to act on.
Those are not pure nearest-neighbor questions.
They are state reconstruction questions.
Where vector-only breaks down
1. Similar does not mean current
A stale decision and its replacement can both be semantically close to the query. If retrieval cannot reason about supersession, the most elegant match may still be the wrong operational answer.
2. Exact names still matter
Project work is full of literal names, file paths, acronyms, identifiers, and product terms. A retrieval stack that throws away lexical recovery gives up useful recall.
3. Evidence quality matters as much as ranking
A production answer should not just sound plausible. It should come with support: provenance, related evidence, and enough context for review.
Accord Book's default retrieval story
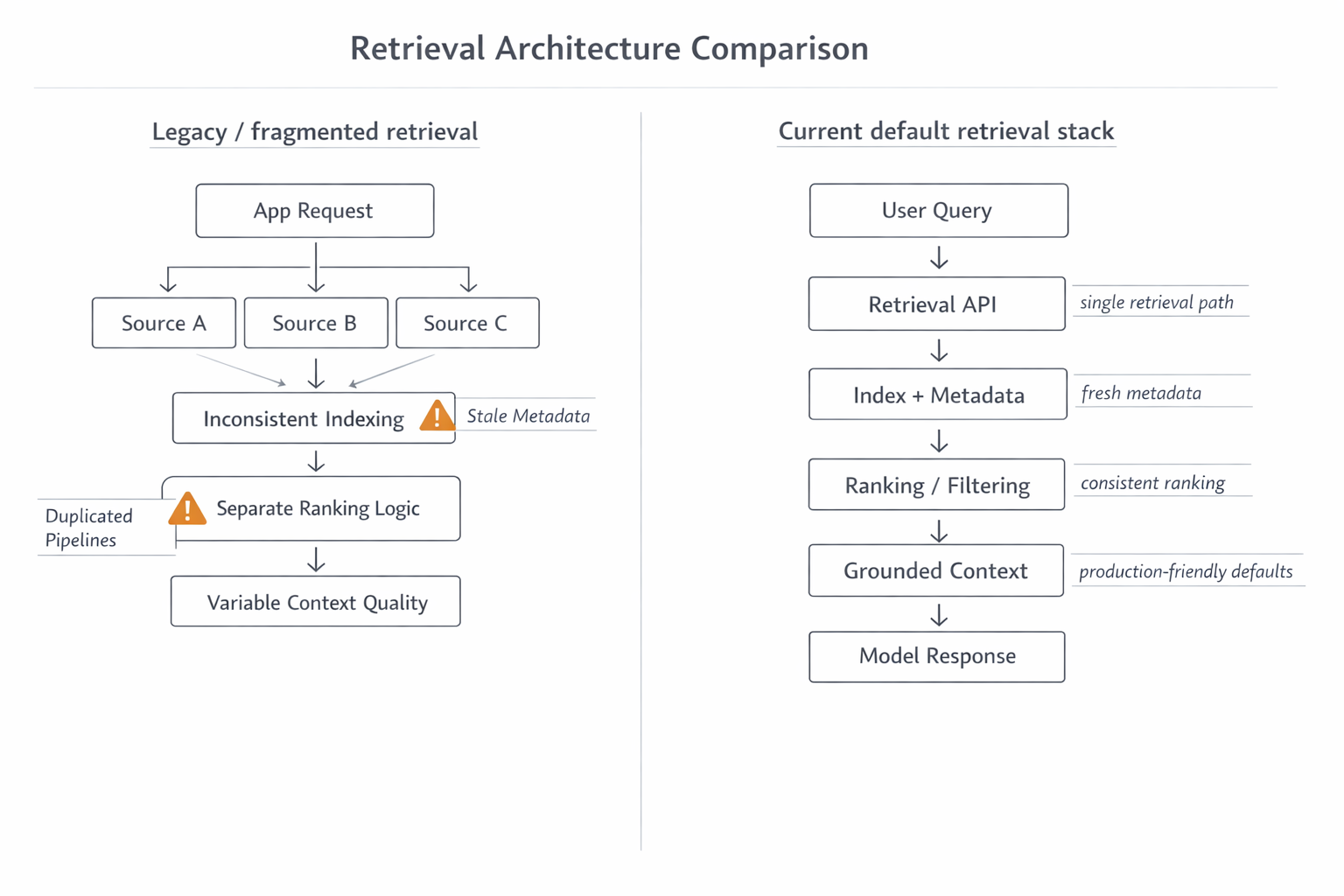
The current retrieval implementation docs describe the default production surface more narrowly than older graph-heavy framing.
The default path is:
- vector retrieval from canonical stored units,
- lexical retrieval as a resilience and exact-match lane,
- supersedes-aware reranking so stale context does not outrank newer authoritative context by accident.
That matters because Accord Book is trying to reconstruct changing project truth, not just answer semantic trivia.
Why lexical recovery belongs in production
Lexical search is sometimes treated like a fallback for when embeddings disappoint.
That is the wrong frame.
In production systems, lexical recovery is part of the core design because it helps with:
- exact names,
- code or product identifiers,
- acronyms,
- sparse but high-value references,
- and cases where the user is asking for something explicit rather than conceptually similar.
The stronger framing is not "vector versus lexical."
It is: use both where each is structurally good at the problem.
Why supersedes-aware reranking matters
Project truth changes over time.
And recency alone is not enough.
Sometimes the right relationship is not "newer" but "this item supersedes that item." A production retrieval system should understand the difference between:
- historical context worth preserving,
- stale context that should be down-ranked,
- and current state that should lead the answer set.
That is why supersedes-aware reranking is such an important part of the current Accord Book retrieval story. It is not an optimization bolt-on. It is part of the answer to the core problem.
Where graph fits now
The current repo documentation is explicit: graph is not the default retrieval lane today.
That does not make graph unimportant.
It means graph is better positioned as a derived intelligence layer for:
- provenance traversal,
- change impact,
- entity disambiguation,
- ownership reasoning,
- and structured project exploration.
That is a better fit than forcing graph to be the public default explanation for memory recall.
Retrieval is a workflow dependency, not just a search primitive
In Accord Book, retrieval is connected to real workflow surfaces:
- owner review,
- conflict detection inputs,
- agent preflight,
- client-safe digests,
- and project-context /
.q_contextgeneration.
That is why retrieval quality is not just about top-k similarity. It shapes what downstream systems see, what they can justify, and what they should be allowed to propose.
Vector-only vs production retrieval
| Capability | Vector-only | Accord Book's current production framing |
|---|---|---|
| Semantic similarity | Strong | Strong |
| Exact-name recovery | Inconsistent | Improved via lexical lane |
| Current-state handling | Weak | Stronger via supersedes-aware reranking |
| Provenance-rich answerability | Limited | Better supported |
| Graph intelligence | Usually absent | Available as a secondary/derived layer |
| Workflow fit | Search-centric | Review, digest, and preflight oriented |
The practical takeaway
The goal of production retrieval is not to find text that looks related.
The goal is to assemble current, supportable, workflow-usable context.
That is why a serious retrieval system usually ends up needing more than vector search alone.
For Accord Book, that story is:
- vector retrieval,
- lexical recovery,
- supersedes-aware reranking,
- provenance-linked evidence,
- and workflow surfaces that keep humans in control of important decisions.
For the benchmark results, read Accord Book Retrieval Benchmarks: What the April 2026 Run Showed. If you want the graph-positioning angle, read How We Decide When Graph Belongs on the Retrieval Path.